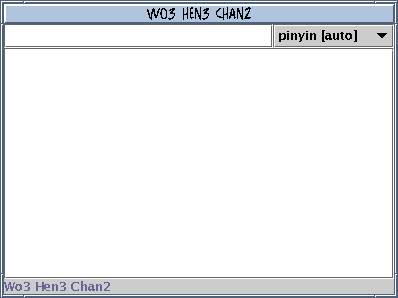
I'm picturing something along the following lines:
As you type/cut & paste in the text field, the area below shows you stays up to date with the most relevant results to the item that you typed into the text field. The text field displays its data in a comprehensible format (e.g. GB2312 data pasted directly into the text field (and displayed and interpreted as such) should be displayed as chinese glyphs).
Data sources should be located with a minimum amount of assistance from the user. If a canonical URL exists for a particular data source that must be mirrored to the user's computer, the URL should be known ahead of the time by the program.
The pulldown in the upper right represents the "encoding" of the input. The pulldown has two modes, autodetect mode and manual mode.
In autodetect mode, the pulldown displayed field is based on the input in the text field, and perhaps some sort of user history, if we wanted to get fancy. In this mode, the pulldown displays the input type name followed by the string "[auto]."
For example:
If the user typed in 'x', the pulldown would display pinyin[auto]
(since 'x' is more likely to be the start of a pinyin than of an
english word). The user types in 'y', and the pulldown switches to
displaying english[auto].
If the user clicks on the pulldown, the pulldown items would be:
In manual mode, the displayed encoding is also one of the pulldown selections. The only way for the selection to change is if the user manually changes it using the pulldown widget. The selections are the same as in automatic mode, with one addition:
I'm picturing the following modes:
| Name | Encoding |
| English | ISO8859-1 |
| Yale Cantonese | ISO8859-1 |
| Pinyin | ISO8859-1 |
| GB Simplified Chinese | GB2312 |
| HZ (different than rfc 1842?) | HZ-GB-2312 |
| ISO2022 Simplified | ISO-2022-CN |
| ISO2022 Traditional | ISO-2022-CN |
| Big5 Traditional Chinese | BIG5 |
| EUC Traditional Chinese | EUC-TW |
| Unicode (simplified) | UTF-8 |
| Unicode (traditional) | UTF-8 |
| Unicode (passthrough) | UTF-8 |
Are there other encodings that I want? Do the three unicode encodings make sense? (Does unicode have separate spaces for traditional and simplified? Probably... but should check). What about ISO-2022-CN and ISO-2022-CN-EXT? Is it better to define another attribute: simplified vs. traditional?
What about UTF-7 (RFC 1642, 2152)
What about RFC 1815?
Might be a good idea to read RFC 1502
The character map (probably might look something like microsoft's Character Map) provides a non-online, quicker lookup time version of various character charts available in the world (e.g. Unihan).
It has the following goal: